
谷歌 Chrome 浏览器被曝静默下载 4GB AI 模型,清理后仍会自动重启下载
谷歌Chrome被曝在用户不知情下,向符合条件的设备静默推送并下载了4GB的Gemini Nano模型。即便用户手动删除,浏览器仍会后台自动重装,引发技术社区广泛关注。该模型是谷歌为本地设备设计的轻量化大模型,用于支持其争议性功能。
谷歌Chrome被曝在用户不知情下,向符合条件的设备静默推送并下载了4GB的Gemini Nano模型。即便用户手动删除,浏览器仍会后台自动重装,引发技术社区广泛关注。该模型是谷歌为本地设备设计的轻量化大模型,用于支持其争议性功能。

OpenAI与马斯克的法律纠纷中,总裁布罗克曼的私密日记被法庭公开,他被迫宣读摘要。马斯克方以此证明OpenAI背离非营利使命、追求个人财富。布罗克曼痛苦强调日记的隐私性,事件凸显法律战对个人隐私的冲击。

字节跳动旗下火山引擎发布豆包大模型家族首款全模态理解模型Doubao-Seed-2.0-lite,实现视频、图像、音频与文本的原生统一理解,突破单一模态限制。该模型在视觉与逻辑推理能力上表现突出,尤其在物理、医疗等高阶学科复杂推理测试中性能

埃隆·马斯克宣布,其人工智能公司xAI将被解散并更名为SpaceXAI,融入SpaceX整体战略。此前SpaceX于2月收购xAI,旨在结合AI与航天技术,推动太空数据中心部署。新公司将专注于开发太空AI产品,实现技术整合与创新。
Adobe于5月6日推出Acrobat新功能PDF Spaces,将静态PDF转化为互动AI工作空间。用户可整合文档、链接、笔记等内容,利用AI生成摘要和演示文稿,实现信息分享与利用的全新方式。

AMD CEO苏姿丰在2026年Q1财报电话会议中指出,随着代理式AI时代到来,数据中心CPU需求快速增长。传统“一CPU配多GPU”的模式正转向CPU与GPU数量接近一对一,未来CPU甚至可能超过GPU。CPU从主要调度角色变为更核心的计

Anthropic与谷歌达成深度合作,承诺未来五年支付2000亿美元采购云服务和自研芯片算力,占谷歌未来收入承诺的40%以上。这笔巨额交易凸显AI行业极高的算力门槛,同时Anthropic与OpenAI的订单量已主导美国主要云服务市场。

月之暗面(Kimi)即将完成20亿美元新融资,投后估值超200亿美元。今年1-2月已密集完成三轮共19亿美元融资,不到半年累计筹资规模惊人,凸显其作为国产大模型领军企业的强大吸金能力。

月之暗面(Kimi)即将完成约20亿美元新一轮融资,投后估值超200亿美元。本轮由美团龙珠领投,出资超2亿美元,中国移动、CPE源峰等参投。延续年初高频融资节奏,1至2月已连续完成三轮共19亿美元融资,半年内累计融资近40亿美元。
北京智源人工智能研究院联合北京安贞医院、河南医药大学第一附属医院,推出业内首个心脏磁共振多模态诊断智能体BAAI Cardiac Agent。该智能体采用先进Agent技术,实现心脏磁共振影像全流程自动化处理,标志着这一复杂领域正式进入自动
谷歌Chrome近期被曝在未获用户同意的情况下,自动下载约4GB的AI模型文件(用于Gemini Nano功能),导致磁盘空间被占用并引发频繁读写活动,引发隐私与合规质疑。即使用户手动删除,浏览器仍会自动重下载,需额外设置才能阻止。
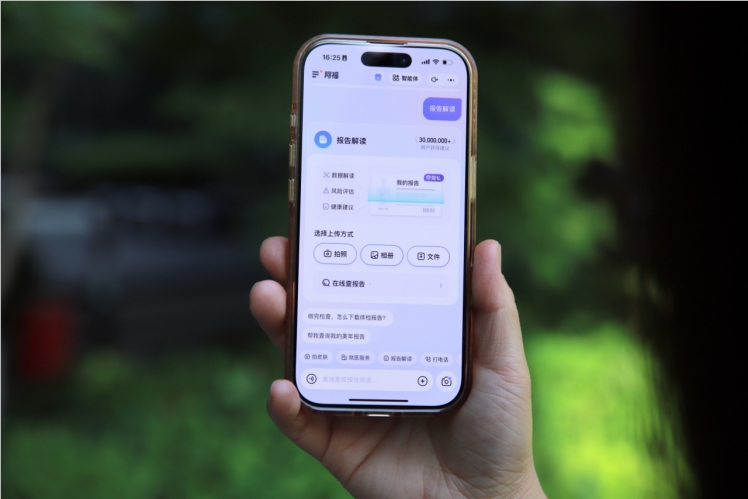
春季体检季,80%受访者称体检报告未获详细解读,75%未按建议复查。5月6日,AI健康应用蚂蚁阿福启动“健康中国体检关怀行动”,为1亿人免费解读报告,用户拍照上传即可获实时分析。

资深电商企业家马克·洛尔(曾创办公司被亚马逊和沃尔玛收购)推出新创企业Wonder,并发布“Wonder Create”计划。该计划利用AI技术,让用户(如食品创业者或社交媒体影响者)在一分钟内设计并推出虚拟餐厅品牌。用户只需输入餐厅类型,

在AI潮玩融资飙升80倍的背景下,泡泡玛特创始人王宁明确表态,旗下核心IP如Labubu、Molly暂不增加AI交互功能。公司坚持“情绪经济”核心逻辑,认为潮玩的灵魂在于情感承载,避免因技术介入导致体验“降维”,这一冷静逆行在科技风口下格外

00后大学生容海瑞带领团队利用人工智能,将广东产拖鞋销往美日韩等国,营收超300万元。创业初期,他帮助一家因国内滞销而亏损的鞋厂,将鞋子材质、成本及预期售价输入AI系统评分,分析国际市场潜力。这些拖鞋虽在国内不够新潮,却成功打开海外销路。

国家集成电路产业投资基金正与DeepSeek洽谈首轮融资,有望主导投资,目标估值接近450亿美元,较初期200亿美元翻倍。尽管DeepSeek当前以大模型研发为主,商业化有限,但投资者对其长期增长前景看好。

深度搜索能力是当前大模型领域的核心竞争点,但传统开发模式依赖资源密集的预训练、微调和强化学习,长期被工业巨头垄断。近日,学术界团队推出OpenSeeker-v2,打破常规,通过高质量方法显著降低资源消耗,展示了高效创新的新路径。

SAP近日宣布收购成立仅18个月的德国初创公司Prior Labs,并计划未来四年投入约10亿欧元,打造专注于结构化数据的企业AI实验室。此举旨在弥补大语言模型在处理表格数据等企业核心业务流程中的短板,将AI应用从文本转向企业数据命脉。

Soul在冲击IPO关键期发布年度生态安全报告,展示其利用七大自研AI模型构建的社交防护体系。这些模型全天候拦截虚假违规信息,通过技术反诈与治理能力,成为公司核心竞争力的重要组成部分。

据分析师郭明錤透露,OpenAI 首款手机计划于2027年初量产,搭载定制版联发科天玑9600处理器,配备增强型HDR图像信号处理器,旨在提升智能体验和视觉效果。